That's a clear testament to scalability when you consider the speed improvement in the last 30 years using basically the same ISA.
It's scaled that way until now. We've hit a power wall in the last few years: as you increase the number of transistors on chip it gets more difficult to distribute a faster clock synchronously, so you increase the power, which is why Nehalem is so power hungry, and why you haven't seen clock speeds really increase since the P4. In any case, we're talking about parallelism, not just "increasing the clock speed" which isn't even a viable approach anymore.
When you said "Compact" I assumed you meant the instruction set itself was compact rather than the average length- I was talking about the hardware needed to decode, not necessarily code density. Even so, x86 is nothing special when it comes to density, especially considered against things like ARM's Thumb-2.
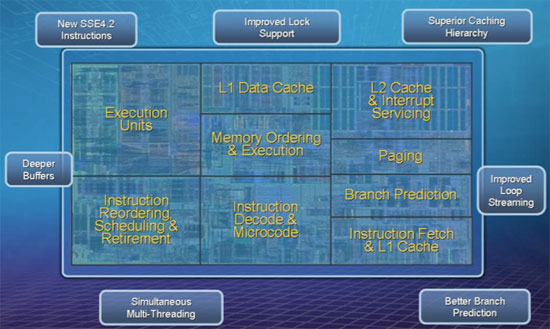
If you take look at Nehalem's pipeline, there's a significant chunk of it simply dedicated to translating x86 instructions into RISC uops, which is only there for backwards compatability. The inner workings of the chip don't even see x86 instructions.
Sure you can do everything the same with shared memory and channel comms, but if you have a multi-node system, you're going to be doing channel communcation anyway. You also have to consider that memory speed is a bottleneck that just won't go away, and for massive parallelism on-chip networks are just faster. In fact, Intel's QPI and AMD's HyperTransport are examples of on-chip network- they provide a NUMA on Nehalem and whatever AMD have these days. Indeed, in the article, it says
Mattson has argued that a better approach would be to eliminate cache coherency and instead allow cores to pass messages among one another.
The thing is, if you want to put more cores on a die, you need either a bigger die or smaller cores. x86 is stuck with larger cores because of all the translation and prediction it's required to do to be both backwards compatible and reasonably well-performing. If you're scaling horizontally like that, you want the simplest core possible, which is why this chip only has 48 cores, and Clearspeed's 2-year-old CSX700 had 192.

{kind=link}
{kind=link}